Cloud Pak for Data - Watson Studio Quickstart¶
Introduction¶
The instructions in this section will walk you through the steps necessary for setting up a demo environment that can be quickly shown to customers to showcase the art of the possible.
This demo in no way removes the need for following the tutorial style instructions that are documented in other sections of this guide. The instructions below will set up a pre-canned application demo environment to show to the customers.
Pre-requisites¶
Create a custom Git Organization¶
Create a new Git Organization to host the different GitOps repositories.
Note
Make sure you do not populate your GitHub organization with cloned repositories. The GitHub organization must be empty and will be populated automatically by the environment provisioning.
Instructions:
-
Log in to http://github.com and select the option to create a New organization.
-
Click on
Create a free organizationplan. -
Complete the wizard by filling in the
Organization account nameandContact emailfields. Select theMy personal accountbullet and complete the verification step and click Next. -
Skip the step to add members to the Organization.
-
Complete the
Welcome to GitHubquestionnaire and click Submit. -
Congratulations, you have successfully created a new Github Organization.
Note
Please ensure your GitHub organization is Public and not Private.
Create a Git Personal Access Token (PAT)¶
Create a new Git Personal Access Token with the appropriate scopes. This will be required to run the application pipelines or to set up webhooks.
Instructions:
-
Log in to http://github.com and click on Settings.
-
Select Developer settings and click on Personal access tokens.
-
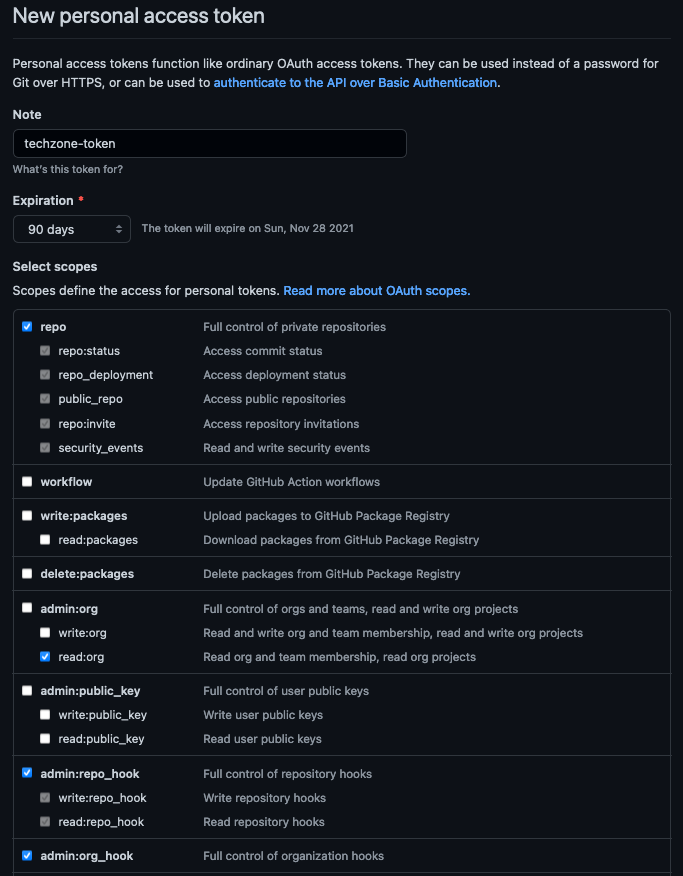
Provide a name for the token, set the
Expirationto 90 days ,set the following scopes and click Generate token.GitHub Personal Access Token scopes
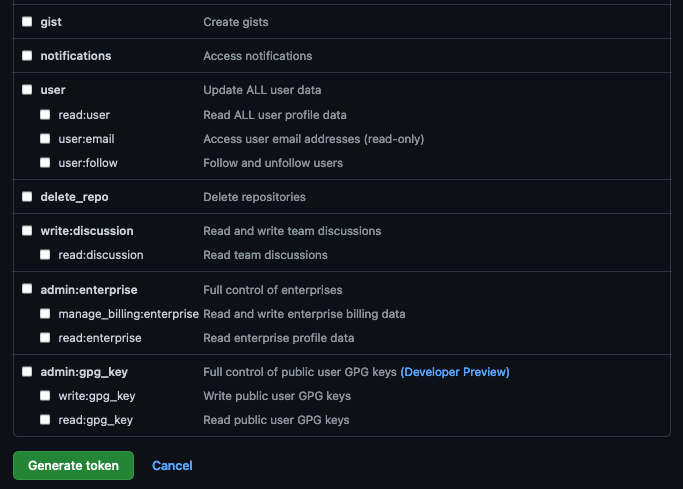
-
Copy and save the Personal Access Token. You will not be able to retrieve this value again later.
Red Hat OpenShift on IBM Cloud cluster with GitOps Configuration¶
Create the cluster¶
-
Provision a Red Hat OpenShift on IBM Cloud cluster with GitOps Configuration from IBM Technology Zone. Select the
OpenShift + GitOps Configurationtile. -
Click the Reserve now radio button.
-
Provide a name for the cluster, select Practice / Self-Education for the purpose and choose the region to provision the cluster.
-
Once a Preferred Geography has been selected, provide the appropriate Worker Node Count and Worker Node Flavor values based on the requirements for this quickstart listed in the note below. Finally, click Submit.
Note
For this Cloud Pak for Data - Watson Studio Quickstart we recommend you to request the Red Hat OpenShift on IBM Cloud cluster with GitOps Configuration with the following size:
- Worker Node Count = 5
- Worker Node Flavor = 16 vCPU x 64 GB - 300 GB Secondary Storage
- NFS Size = 1 TB
Use the cluster¶
You will receive an email once the cluster provisioning is complete. The email will contain details on the cluster including the ArgoCD Console URL and admin credentials. This same information can also be found on the My reservations from IBM Technology Zone.
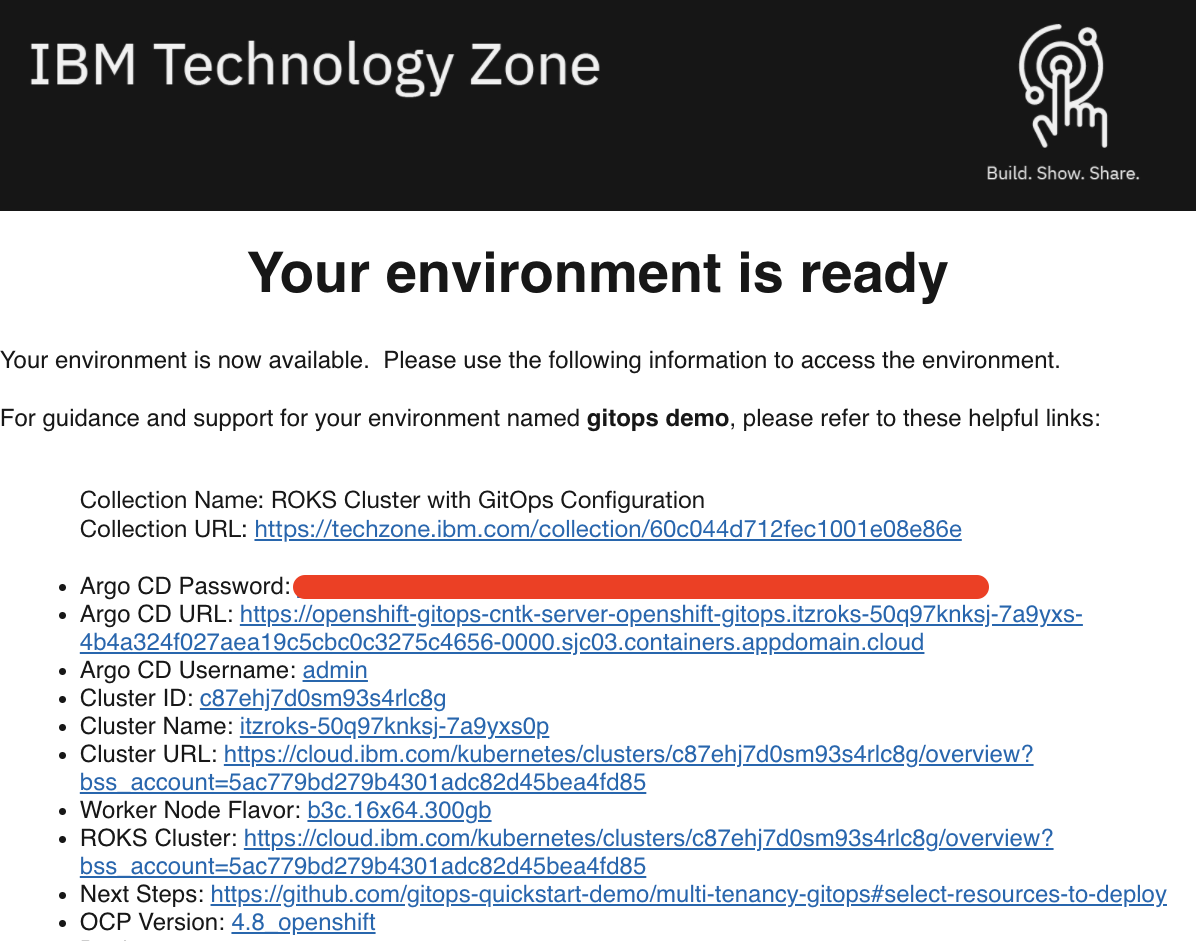
Once your cluster is ready, proceed to the next step to select resources to deploy.
Install required CLIs¶
- Install the Github CLI (version 1.14.0+)
-
Install the OpenShift CLI
oc(version 4.7 or 4.8)-
Log into your OCP cluster, substituting the
--tokenand--serverparameters with your values:oc login --token=<token> --server=<server>If you are unsure of these values, click your user ID in the OpenShift web console and select
Copy login command.
-
-
Install the kubeseal CLI
The kubeseal utility uses asymmetric crypto to encrypt secrets that only the controller can decrypt. These encrypted secrets are encoded in a SealedSecret resource which can safely be checked into your gitops repo. The controller will decrypt the secretes and install into your cluster.
Select resources to deploy¶
By now, you should already have a Red Hat OpenShift on IBM Cloud cluster with GitOps Configuration bootstrapped for you.
If you open ArgoCD, which is the GitOps tool being installed by the Red Hat OpenShift GitOps Operator, using the Argo CD URL provided in the email shown in the previous section, you will see that your ArgoCD GitOps application has been bootstrapped to monitor the multi-tenancy-gitops repository that has been forked into the GitHub organization you provided when requesting the quickstart environment.
As a result, anything you want to apply/do to your quickstart environment will be done through code changes on the aforementioned forked GitHub repository.
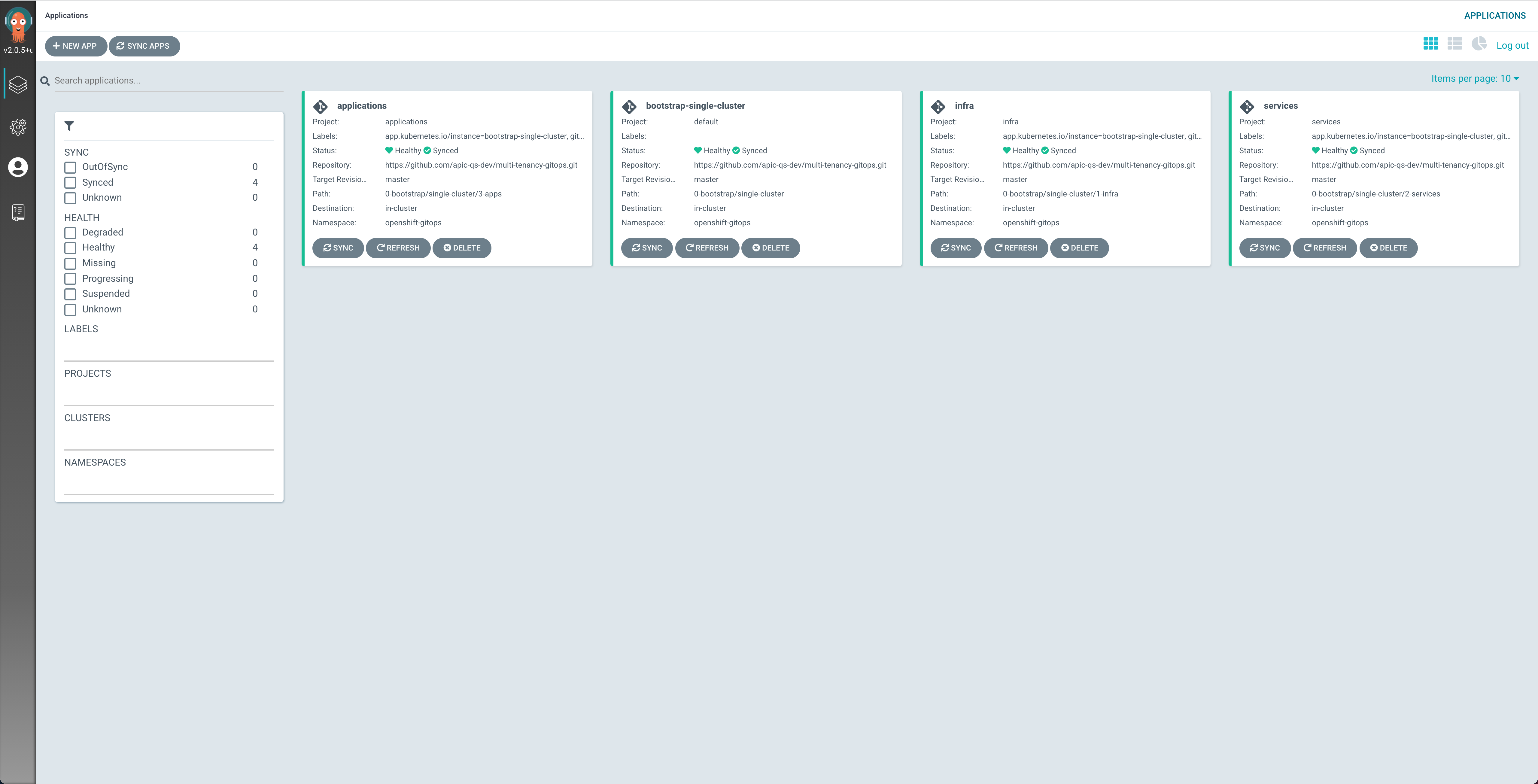
You can see in the image above of your ArgoCD web console that the profile within the multi-tenancy-gitops repository ArgoCD has been bootstrapped with is the single-cluster. As a result, anything you want to apply/do to your quickstart environment will be done within that GitOps profile.
You can also see that the ArgoCD applications for the infrastructure, services and applications layers are already created so that these will pick up any changes done, through code, at their respective layers.
Instructions¶
When you made the Red Hat OpenShift on IBM Cloud cluster request in the earlier section, automation has forked multi-tenancy-gitops GitHub repository into your GitHub organization, the name of which you provided in the cluster request form. You can execute the following steps either locally by cloning the multi-tenancy-gitops repository from your GitHub organization to your local workstation (and then make changes from you local workstation and commit and deliver those) or by using the new VSCode extension of GitHub Codespaces capability straight from your web browser (just open the multi-tenancy-gitops repository in your GitHub organization in your browser and press the . key):
Note
For this guide, when following the instructions in the recipe below, consider GITOPS_PROFILE="0-bootstrap/single-cluster".
-
Review the
Infrastructurelayer kustomization.yaml and un-comment the resources to deploy to match the Cloud Pak for Data - Watson Studio recipe. -
Review the
Serviceslayer kustomization.yaml and un-comment the resources to deploy to match the Cloud Pak for Data - Watson Studio recipe. -
Commit and push changes to your git repository (the following code refers to the commands when you cloned the
multi-tenancy-gitopsrepository locally on your workstation)
git add .
git commit -m "initial bootstrap setup"
git push origin
Verifying the Installation¶
-
After approximately 30 minutes, get the status of the control plane (lite-cr)
oc get ZenService lite-cr -n tools -o jsonpath="{.status.zenStatus}{'\n'}"Cloud Pak for Data control plane is ready when the command returns
Completed. If the command returns another status, wait for some more time and rerun the command. -
After approximately 2 hours, Get the status of Watson Studio (ws-cr)
oc get WS ws-cr -n tools -o jsonpath="{.status.wsStatus} {'\n'}"Watson Studio is ready when the command returns
Completed.
Cloud Pak for Data UI¶
-
Get the URL of the Cloud Pak for Data web client and open it in a browser.
echo https://`oc get ZenService lite-cr -n tools -o jsonpath="{.status.url}{'\n'}"` -
The credentials for logging into the Cloud Pak for Data web client are
admin/<password>where password is stored in a secret.oc extract secret/admin-user-details -n tools --keys=initial_admin_password --to=- -
Log into the IBM Cloud Pak for Data UI using the password from previous step.
-
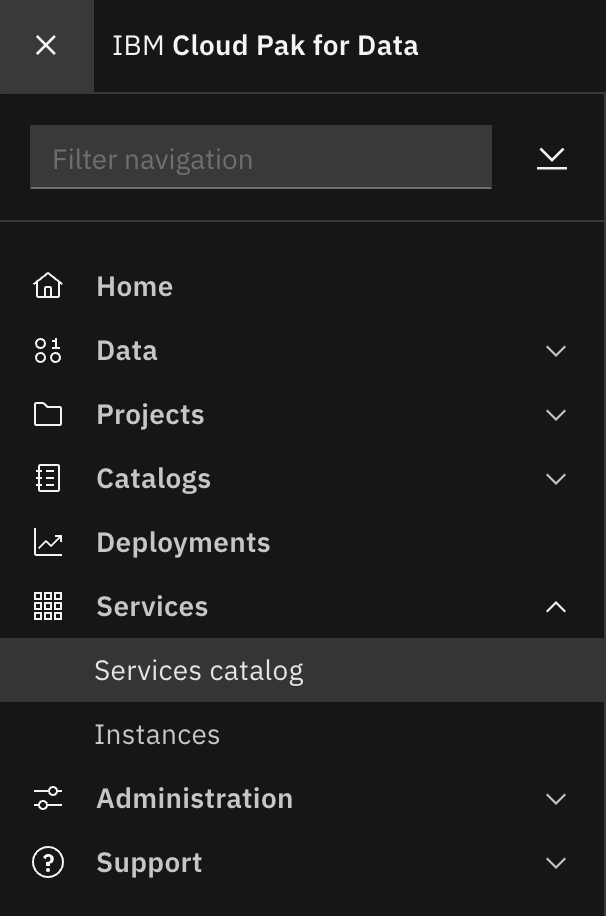
Click on the navigation menu icon on the top left corner. Click on Services menu option to expand it, then select Services catalog.
-
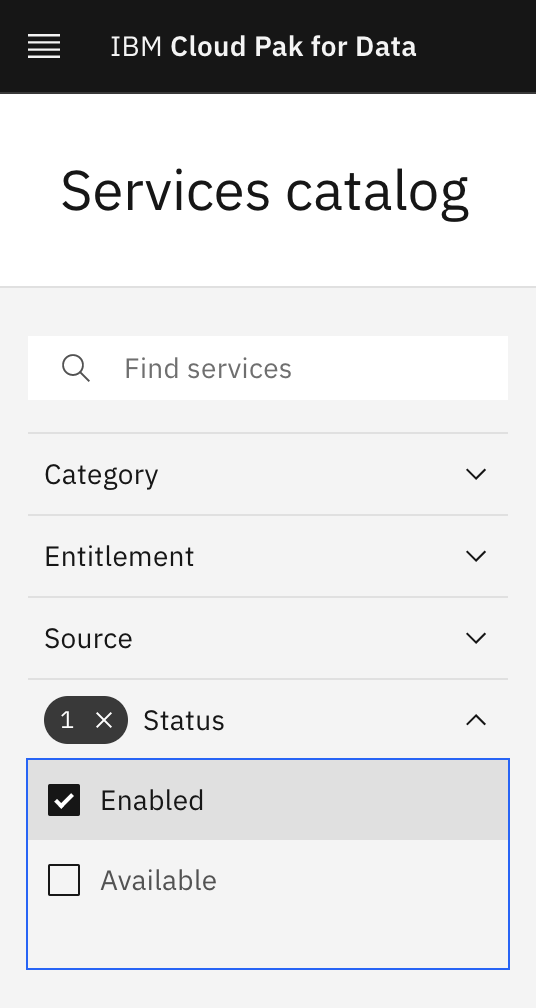
Under Status, select "Enabled" to display only the services that are installed and enabled in Cloud Pak for Data.
-
Notice the
Enabledtag next to Watson Studio. There might be other enabled services as well.