Creating a cluster on IBM Cloud¶
Abstract
This document explains what are the options to create a Red Hat OpenShift cluster on IBM Cloud.
Create a Red Hat OpenShift cluster instance.¶
You can choose either IBM Technology Zone or your IBM Cloud account to create a Red Hat OpenShift cluster.
- You can use IBM Technology Zone to request a Red Hat OpenShift cluster on IBM Cloud. See the instructions here. The Red Hat OpenShift cluster on IBM Cloud you will be provided with will be hosted on classic infrastructure.
- You can use your IBM Cloud account to create a new Red Hat OpenShift cluster following these instructions here. You can choose to create your Red Hat OpenShift cluster on IBM Cloud either on classic infrastructure or on Virtual Private Cloud (VPC) infrastructure.
Important
Make sure you create your Red Hat OpenShift cluster on IBM Cloud with the following specs as explained here:
- OCP Version = 4.7
- Worker Size (at least) = 24 CPU x 96 GB RAM
- Worker Node Count (at least) = 1
- Storage = 200 GB
Note
Even though you do not require 3 worker nodes, since the IBM Process Mining instance you will deploy in this tutorial isn't a highly available IBM Process Mining instance due to the amount of resources required, the Red Hat OpenShift clusters you usually request or create come with 3 worker nodes for better high availability and resiliency purposes. Make sure you comply with the specs above when adding the resources of each worker node.
Storage¶
As explained in the IBM Process Mining on IBM Cloud architecture section here, IBM Process Mining requires ReadWriteMany (RWX) storage.
Based on how you created your Red Hat OpenShift cluster on IBM Cloud explained in the previous section,
- If you requested your Red Hat OpenShift cluster through IBM Technology Zone, this will be a Red Hat OpenShift cluster on IBM Cloud on classic infrastructure which an NFS drive will be attached to. The storage class name will be managed-nfs-storage and it is the default in the GitOps repositories that will drive the deployment of your IBM Process Mining instance which are explained in the next sections.
- If you requested a Red Hat OpenShift cluster on IBM Cloud using your own IBM Cloud account,
- If you requested that Red Hat OpenShift cluster on IBM Cloud classic infrastructure, you will have RWX storage available out of the box. However, you must use those file storage classes whose name ends with -gid to allow non-root user access to persistent storage, which is a requirement for the embedded IBM DB2 DB that IBM Process Mining will deploy (if using external IBM DB2 database, as explained in the IBM Process Mining on IBM Cloud architecture section here, you would not need to use the storage classes whose name ends with -gid. Just any file storage class)
- If you requested that Red Hat OpenShift cluster on IBM Cloud Virtual Private Cloud (VPC) infrastructure, you must enable OpenShift Data Foundation for your Red Hat OpenShift cluster. Review the IBM Process Mining on IBM Cloud architecture section here for more details and go through the following OpenShift Data Foundation subsection to get it enabled on your Red Hat OpenShift cluster.
Remember
Do not forget the RWX storage class name based on the above as you will need to provide it when deploying your IBM Process Mining instance later in this tutorial.
OpenShift Data Foundation¶
-
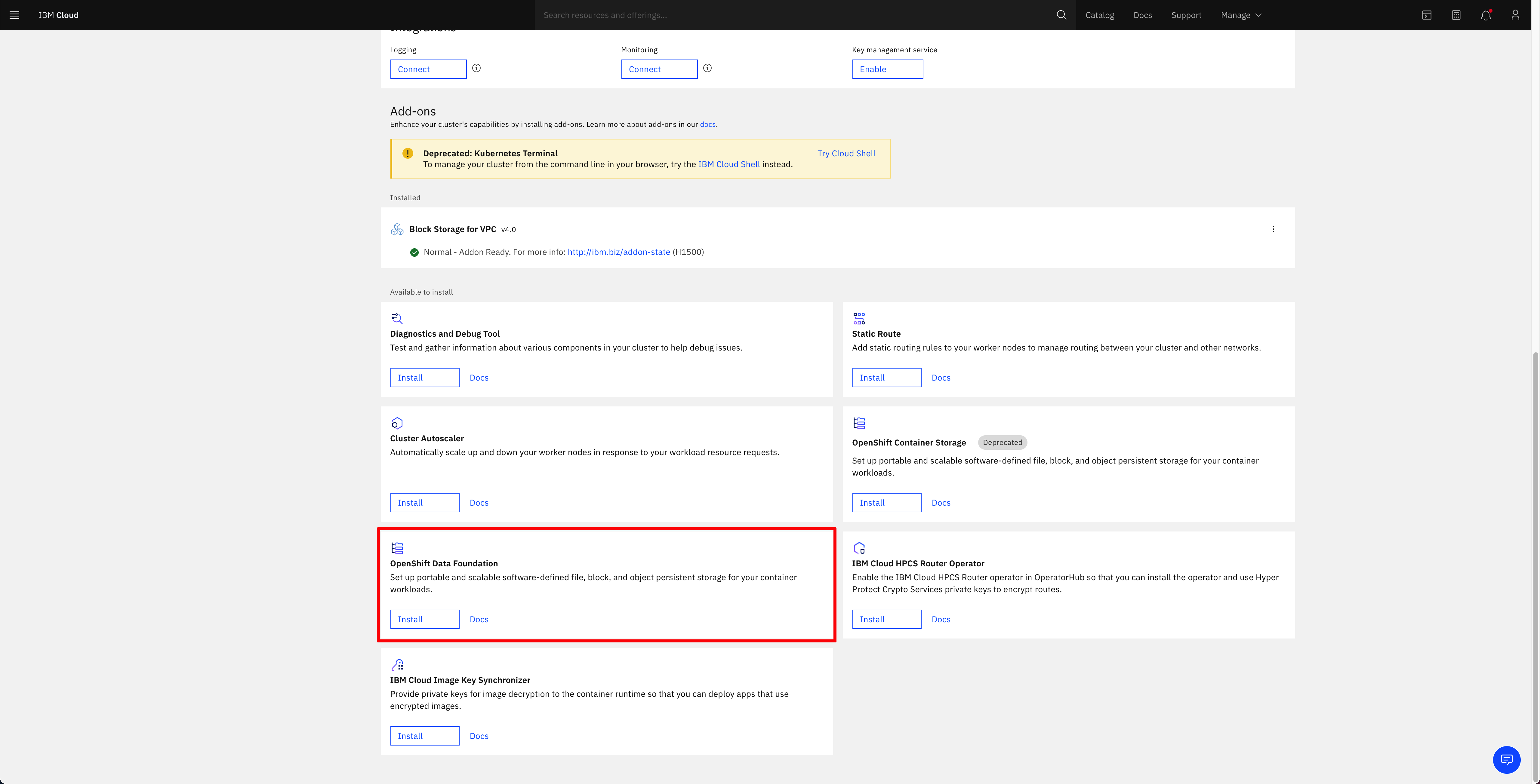
Once your RedHat OpenShift cluster on IBM Cloud Virtual Private Cloud infrastructure is available on your IBM Cloud dashboard, you must install the OpenShift Data Foundation add-on on it:
- From the OpenShift clusters console, select the cluster where you want to install the add-on.
- On the cluster Overview page, scroll down to the Add-ons section.
- On the OpenShift Data Foundation card, click Install.
-
On the Install OpenShift Data Foundation configuration panel that opens, make sure of
- The parameter
ocsDeployis set totrue - The parameter
numOfOsdis set to1 - The parameter
monStorageClassNameandosdStorageClassNameis set to any of the metro storage classes provided by IBM Cloud as explained in the IBM Process Mining Architecture on IBM Cloud page here
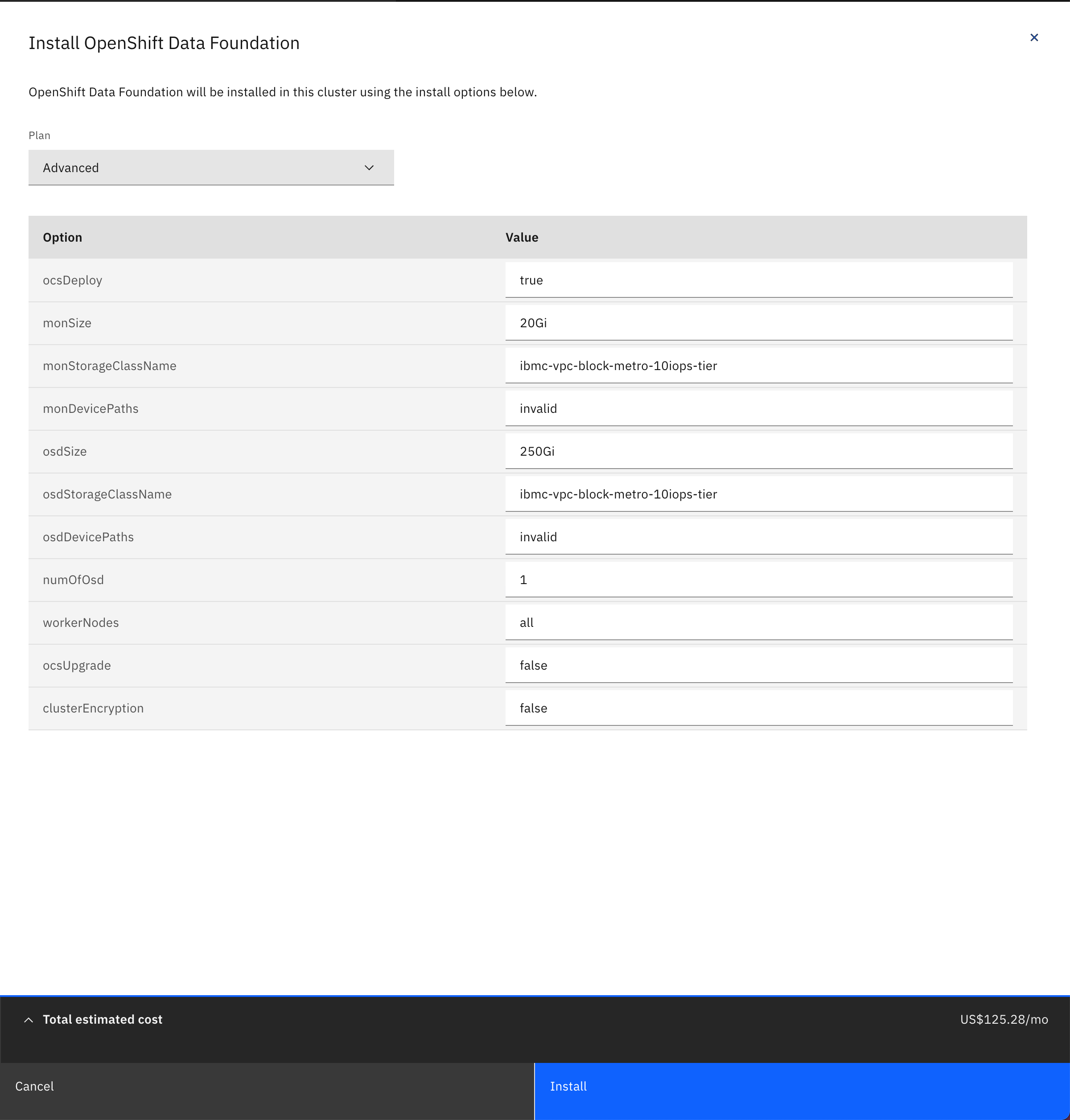
- The parameter
-
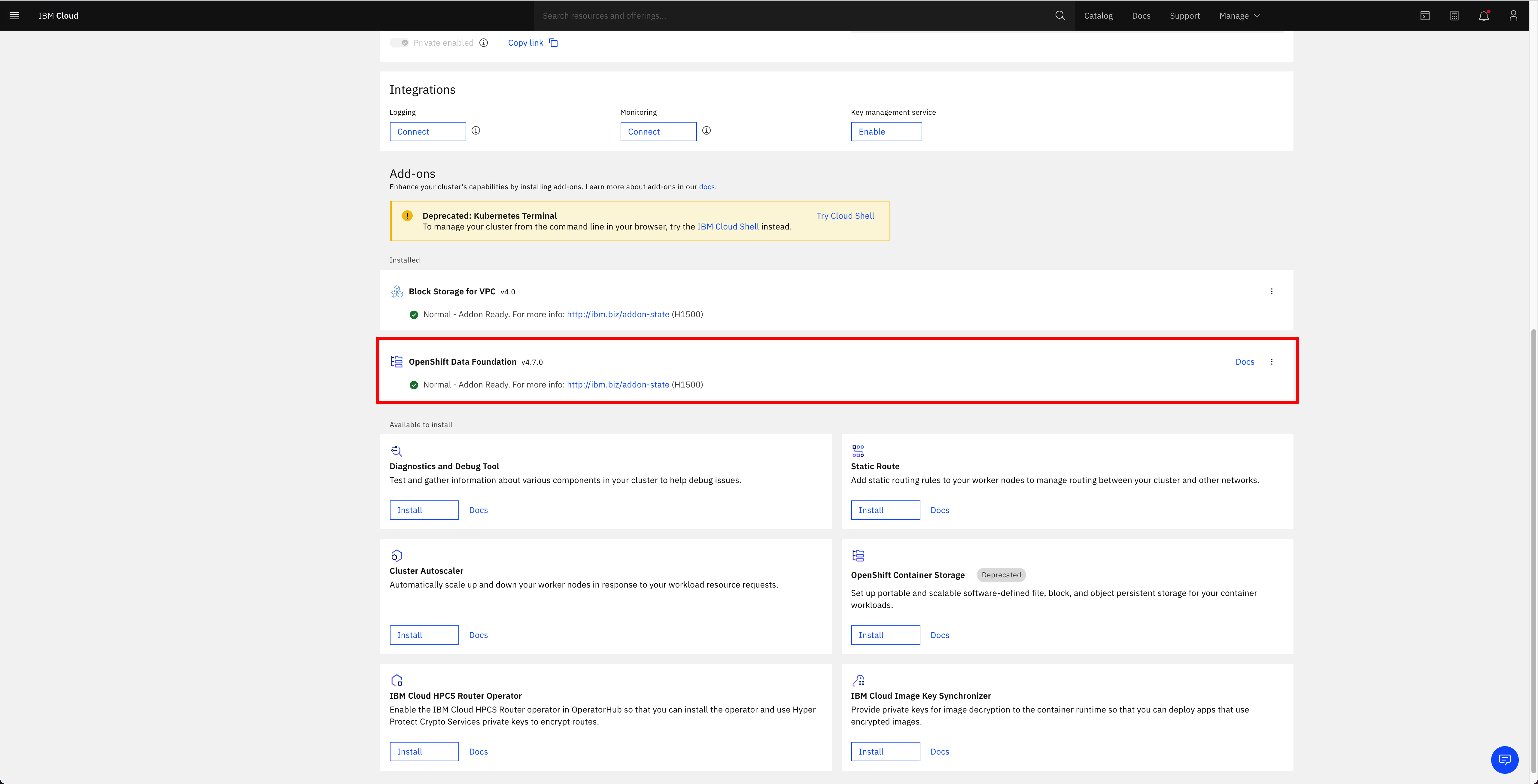
Click Install. This should get OpenShift Data Foundation installation for your cluster started. After some time, you should see the OpenShift Data Foundation add-on under the installed subsection of the Add-ons section of your OpenShift cluster in the IBM Cloud web console with a green tick icon indicating the add-on is fine and ready (this process may take several minutes)
-
If you go into your OpenShift cluster web console and go to
Operators --> Installed Operatorson the left hand side menu, you should see the OpenShift Container Storage (old name for OpenShift Data Foundation) operator installed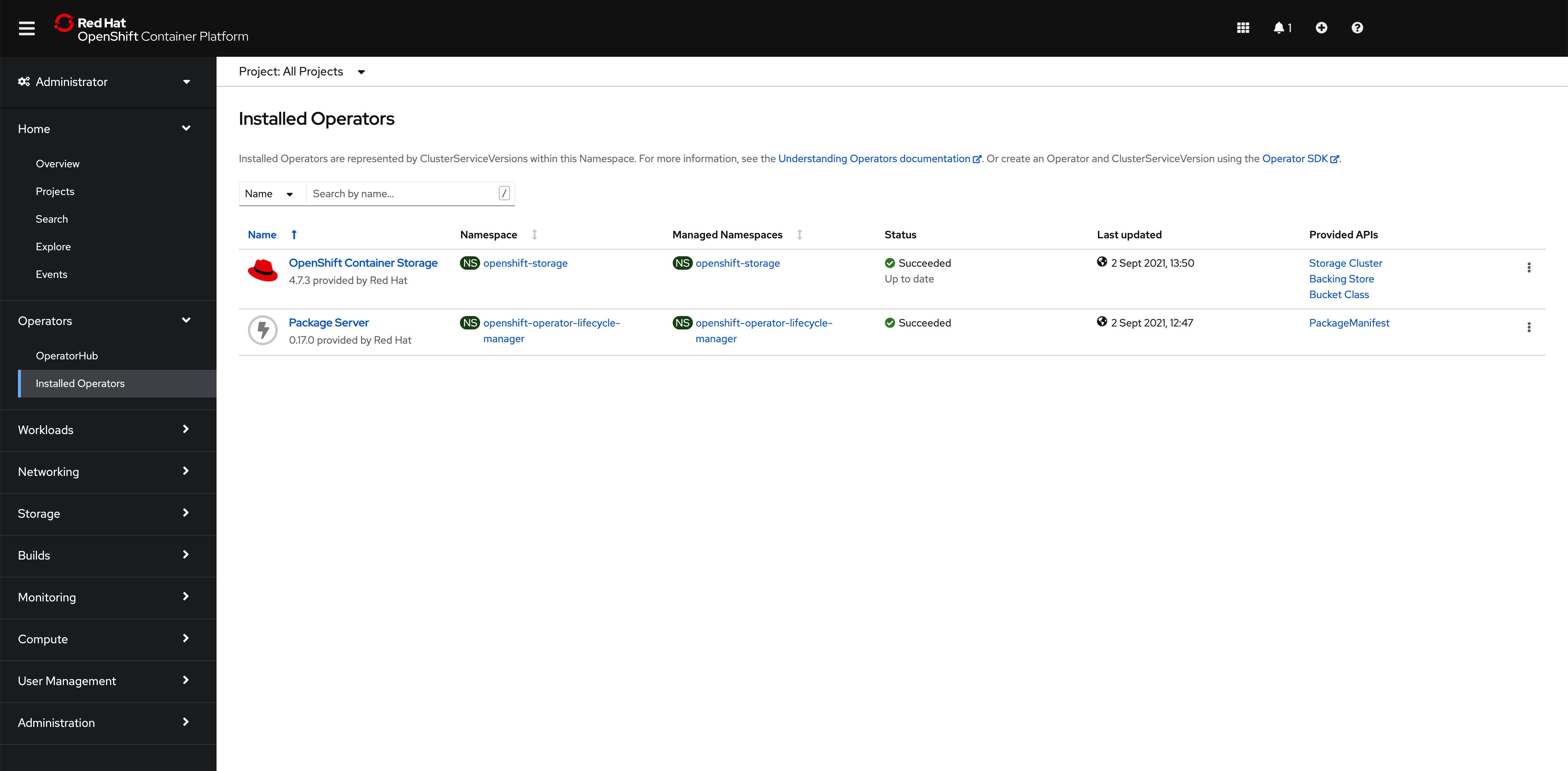
-
Finally, if you go to
Storage --> Storage Classeson the left hand side menu, you should see the following four new storage classes as a result of a successful OpenShift Data Foundation installation. These are the classes you should now use in your containerized workloads should you need File, Block or Object storage.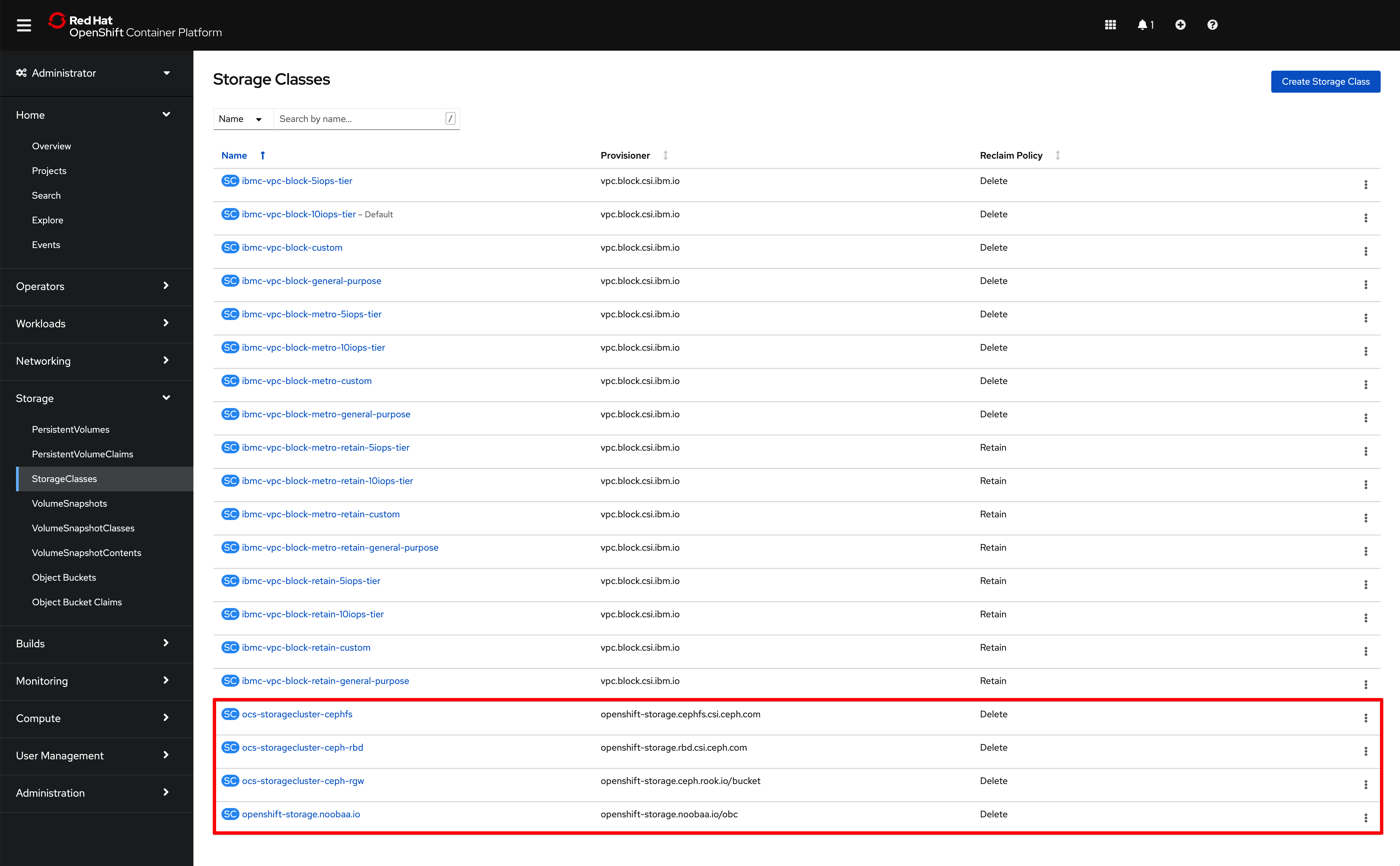
And the storage class you would need to provide when deploying your IBM Process Mining instance later on in this tutorial would be ocs-storagecluster-cephfs
Tools¶
In order to interact with your Red Hat OpenShift cluster(s) and complete this tutorial successfully, we strongly recommend to install the following tools in your workstation.
- The
occommand that matches the version of your cluster. Use these instructions to get the latest version ofoc. Useoc versionto confirm that you haveClient Version: 4.6or higherServer Version: 4.7or higher
- The
npm,git,treeandjqcommands.